假設我們現在有操作系統提供的 U ( 0 , 1 ) U(0,1) U ( 0 , 1 )
Box-Muller 轉換
U 1 , U 2 ∼ iid U ( 0 , 1 ) U_1, U_2 \stackrel{\text{iid}}{\sim} U(0,1) U 1 , U 2 ∼ iid U ( 0 , 1 )
X = − 2 ln U 1 cos ( 2 π U 2 ) Y = − 2 ln U 1 sin ( 2 π U 2 ) \begin{align*}
X &= \sqrt{-2 \ln U_1} \cos(2\pi U_2) \\
Y &= \sqrt{-2 \ln U_1} \sin(2\pi U_2)
\end{align*} X Y = − 2 ln U 1 cos ( 2 π U 2 ) = − 2 ln U 1 sin ( 2 π U 2 ) 則 X , Y ∼ iid N ( 0 , 1 ) X, Y \stackrel{\text{iid}}{\sim} N(0,1) X , Y ∼ iid N ( 0 , 1 )
基本原理
这可以通过 Jacobian 计算得到。
∂ ( X , Y ) ∂ ( U 1 , U 2 ) = ∣ − 2 2 U 1 − 2 ln U 1 cos ( 2 π U 2 ) − 2 ln U 1 ( − 2 π sin ( 2 π U 2 ) ) − 2 2 U 1 − 2 ln U 1 sin ( 2 π U 2 ) − 2 ln U 1 ( 2 π cos ( 2 π U 2 ) ) ∣ = − 1 U 1 2 π cos 2 ( 2 π U 2 ) − 1 U 1 2 π sin 2 ( 2 π U 2 ) = − 2 π 1 U 1 ⟹ J = ∂ ( U 1 , U 2 ) ∂ ( X , Y ) = − U 1 2 π \begin{align*}
&\begin{align*}
\frac{\partial (X,Y)}{\partial (U_1, U_2)} &=
\begin{vmatrix}
\frac{-2}{2U_1\sqrt{-2\ln U_1}} \cos(2\pi U_2) & \sqrt{-2\ln U_1} (-2\pi \sin(2\pi U_2)) \\
\frac{-2}{2U_1\sqrt{-2\ln U_1}} \sin(2\pi U_2) & \sqrt{-2\ln U_1} (2\pi \cos(2\pi U_2)) \\
\end{vmatrix}
\\
&= -\frac{1}{U_1} 2\pi \cos^2(2\pi U_2) - \frac{1}{U_1} 2\pi \sin^2(2\pi U_2) \\
&=-2\pi \frac{1}{U_1}
\end{align*}\\
&\implies J = \frac{\partial (U_1, U_2)}{\partial (X,Y)} =-\frac{U_1}{2\pi}
\end{align*} ∂ ( U 1 , U 2 ) ∂ ( X , Y ) = 2 U 1 − 2 l n U 1 − 2 cos ( 2 π U 2 ) 2 U 1 − 2 l n U 1 − 2 sin ( 2 π U 2 ) − 2 ln U 1 ( − 2 π sin ( 2 π U 2 )) − 2 ln U 1 ( 2 π cos ( 2 π U 2 )) = − U 1 1 2 π cos 2 ( 2 π U 2 ) − U 1 1 2 π sin 2 ( 2 π U 2 ) = − 2 π U 1 1 ⟹ J = ∂ ( X , Y ) ∂ ( U 1 , U 2 ) = − 2 π U 1 均勻分佈的機率在有效區間內是常數,所以我們不需要關心 U 1 , U 2 U_1,U_2 U 1 , U 2 J J J U 1 U_1 U 1 U 1 = exp X 2 + Y 2 − 2 U_1=\exp{\frac{X^2+Y^2}{-2}} U 1 = exp − 2 X 2 + Y 2
f ( X , Y ) ( x , y ) = f ( U 1 , U 2 ) ( g 1 ( x , y ) , g 2 ( x , y ) ) ∣ J ∣ = 1 2 π exp X 2 + Y 2 − 2 = 1 2 π exp X 2 − 2 1 2 π exp Y 2 − 2 f_{(X,Y)}(x,y)=f_{(U_1,U_2)}(g_1(x,y), g_2(x,y))|J| = \frac{1}{2\pi} \exp{\frac{X^2+Y^2}{-2}} = \frac{1}{\sqrt{2\pi}} \exp{\frac{X^2}{-2}} \frac{1}{\sqrt{2\pi}} \exp{\frac{Y^2}{-2}} f ( X , Y ) ( x , y ) = f ( U 1 , U 2 ) ( g 1 ( x , y ) , g 2 ( x , y )) ∣ J ∣ = 2 π 1 exp − 2 X 2 + Y 2 = 2 π 1 exp − 2 X 2 2 π 1 exp − 2 Y 2 得到了兩個獨立的 normal 分佈的聯合概率密度函數,因此 X , Y ∼ iid N ( 0 , 1 ) X, Y\stackrel{\text{iid}}{\sim} N(0,1) X , Y ∼ iid N ( 0 , 1 )
以 U 1 U_1 U 1 U 1 U_1 U 1 U 1 = R cos ( θ ) U_1=R\cos(\theta) U 1 = R cos ( θ ) θ ∼ iid U ( 0 , 2 π ) \theta\stackrel{\text{iid}}{\sim} U(0,2\pi) θ ∼ iid U ( 0 , 2 π ) R 2 = − 2 ln U 1 R^2=-2\ln U_1 R 2 = − 2 ln U 1 χ 2 2 \chi^2_2 χ 2 2
Z 1 2 + Z 2 2 = χ 2 2 = − 2 ln U = − 2 ln U ( cos 2 θ + sin 2 θ ) Z_1^2+Z_2^2 = \chi^2_2 = -2\ln U = -2\ln U (\cos^2\theta+\sin^2\theta) Z 1 2 + Z 2 2 = χ 2 2 = − 2 ln U = − 2 ln U ( cos 2 θ + sin 2 θ ) 代碼實現
use rand :: distributions :: Standard ; use rand :: prelude :: * ; use std :: f64 :: consts :: PI ; fn box_muller ( ) -> f64 { let mut u1 : f64 = StdRng :: from_entropy ( ) . sample ( Standard ) ; let mut u2 : f64 = StdRng :: from_entropy ( ) . sample ( Standard ) ; while u1 == 0.0 { u1 = StdRng :: from_entropy ( ) . sample ( Standard ) ; } while u2 == 0.0 { u2 = StdRng :: from_entropy ( ) . sample ( Standard ) ; } let z1 = ( - 2.0_f64 * u1 . ln ( ) ) . sqrt ( ) * ( 2.0 * PI * u2 ) . cos ( ) ; return z1 ; } Ziggurat 算法
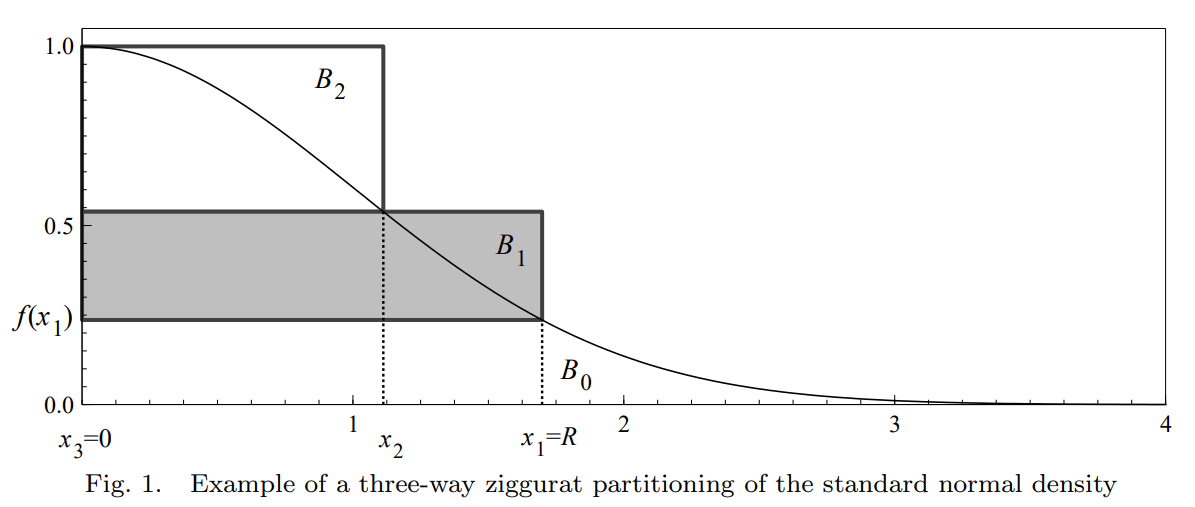
Ziggurat 算法是一種採樣拒絕類的算法。它的基本思想是在平面上畫一個分佈函數的曲線,然後在曲線下隨機生成一個點。幾率高的地方,其曲線下方擁有更多的面積,因此點落在這些地方的概率也更大。因為本身就是以曲線為單位隨機生成點,因此在繪製曲線時可以省略標準化,比如 N ( 0 , 1 ) N(0,1) N ( 0 , 1 ) f ( x ) = exp ( − x 2 / 2 ) f(x)=\exp(-x^2/2) f ( x ) = exp ( − x 2 /2 )
為了加快運行速度,Ziggurat 算法實際上是用許多矩形來逼近分佈函數的圖形,而這些矩形的坐標可以提前計算並儲存,這在生成大量隨機數時可以大大提高效率。
算法假設每個矩形的面積都相同,因此隨機生成的點落在每個矩形的幾率應該是相同的。反過來了,當要隨機生成一個點時,我們可以先公平地隨機選一個矩形,然後再在這個矩形中生成一個點。
從示意圖上可以注意到,矩形可以被分為兩個部分:完全處在曲線下方和部分處在曲線下方。在選擇好矩形後(如圖中 B 1 B_1 B 1 x x x U ( 0 , x 1 ) U(0,x_1) U ( 0 , x 1 ) x < x 2 x<x_2 x < x 2 y y y U ( f ( x 1 ) , f ( x 2 ) ) U(f(x_1),f(x_2)) U ( f ( x 1 ) , f ( x 2 )) y y y y < f ( x ) y<f(x) y < f ( x )
無論矩形的數量如何,尾部總會有無法被完全覆蓋的部分(如圖中 x 1 x_1 x 1
計算矩形
假設我們首先設定了每個矩形的面積都為 V V V B 0 B_0 B 0
x 2 [ f ( x 3 ) − f ( x 2 ) ] = x 1 [ f ( x 2 ) − f ( x 1 ) ] = x 1 f ( x 1 ) + ∫ x 1 ∞ f ( x ) d x = V x_2[f(x_3)-f(x_2)] = x_1[f(x_2)-f(x_1)] = x_1f(x_1) + \int_{x_1}^{\infty}f(x)dx=V x 2 [ f ( x 3 ) − f ( x 2 )] = x 1 [ f ( x 2 ) − f ( x 1 )] = x 1 f ( x 1 ) + ∫ x 1 ∞ f ( x ) d x = V 如果最右的 x 1 x_1 x 1 x 2 x_2 x 2 V V V f ( x 1 ) f(x_1) f ( x 1 )
x 2 = f − 1 ( f ( x 1 ) + V / x 1 ) x_2 = f^{-1}(f(x_1) + V/x_1) x 2 = f − 1 ( f ( x 1 ) + V / x 1 ) 如果我們要用 C C C x C = 0 x_C=0 x C = 0 C − 1 C-1 C − 1 x x x
x i = f − 1 ( f ( x i − 1 ) + V / x i − 1 ) , i = 2 , ⋯ , C − 1 x_i = f^{-1}(f(x_{i-1}) + V/x_{i-1}),\quad i=2,\cdots,C-1 x i = f − 1 ( f ( x i − 1 ) + V / x i − 1 ) , i = 2 , ⋯ , C − 1 可以�從看出 x i x_i x i V V V V V V x 1 x_1 x 1 x 1 x_1 x 1
x C − 1 ( x 1 ) [ f ( x C ) − f ( x C − 1 ( x 1 ) ) ] = V ( x 1 ) x_{C-1}(x_1)[f(x_C)-f(x_{C-1}(x_1))] = V(x_1) x C − 1 ( x 1 ) [ f ( x C ) − f ( x C − 1 ( x 1 ))] = V ( x 1 ) 通過數值方法找到以上方程的解,就可以得到 x 1 x_1 x 1