簡單線性模型(Simple Linear Regression, SLR)
SLR
i=1,⋯,n,Xi∈R1 and E[εi]=0
Yi=β0+β1Xi+εiE[Yi∣X=Xi]=E[β0+β1Xi+εi]=β0+β1Xi=f(Xi,β) 稱為回歸函數(regression function),其中 β=(β0,β1) 是未知參數。
複線性模型(Multiple Linear Model, MLR)
複線性模型與 SLR 類似,但區別在於 Xi=(Xi,1,Xi,2,⋯,Xi,n)∈Rn 是多為向量。
MLR
i=1,⋯,nXn∈Rk,k>1
Yi=β0+β1Xi,1+β2Xi,2+⋯+βkXi,k+εi
-
“線性”是指回歸函數 f(x;β) 中的參數都是線性的。
-
在一些非線性關係中,通過將 X 做一些變換,就也可以用線性模型來分析。
e.g. Y=β0+β1sint+εx=sintY=β0+β1x+ε
我們拿到一組數據 (X1,Y1),⋯,(Xn,Yn),我們假設這組數據是由一個線性模型產生的,即 Yi=β0+βXi+εi,但我們不知道 β,並且 εi 是一個隨機變量。
我們的目標是通過這組數據來估計 β,得到 β^,然后通過 β^ 來得到预测值 Yi^=f(Xi;β^)。
最小二乘估計(Least Squares Estimation, LSE)
残差(residual):ei=Yi−Yi^
我們希望預測值 Yi^ 與實際值 Yi 的差距越小越好,即 ∑i=1nei2=∑i=1n(Yi−Yi^)2 越小越好。為此,我們通常會使用 最小二乘估計(Least Squares Estimation, LSE)。
對於線性回歸 Yi=f(Xi;β)+εi,定義:
Q(β)=i=1∑n(Yi−E[Yi])2=i=1∑n(Yi−f(Xi;β))2稱 b 是 β 的 LSE ⟺Q(b)=minβQ(β)
b0b1=Yˉ−b1Xˉ=∑i=1n(Xi−Xˉ)2∑i=1n(Xi−Xˉ)(Yi−Yˉ)=∑i=1n(Xi−Xˉ)2∑i=1nXi(Yi−Yˉ)=∑i=1n(Xi−Xˉ)2∑i=1n(Xi−Xˉ)Yi ⟹Yi^=b0+b1Xi=Yˉ−b1Xˉ+b1Xi=Yˉ+b1(Xi−Xˉ)。
⟹ei=Yi−Yiˉ=Yi−Yˉ−b1(Xi−Xˉ)
-
∑i=1nei=∑(Yi−Yˉ−b1(Xi−Xˉ))=∑(Yi−Yˉ)−b1∑(Xi−Xˉ)=0
-
∑i=1nYi^=∑(Yˉ−b1(Xi−Xˉ))=nYˉ−b1∑(Xi−Xˉ)
⟹n1∑i=1nYi^=Yˉ, i.e. 預測值的中心點是數據值的中心點。
i=1∑n(Xiei)=i=1∑n[Xi(Yi−Yˉ−b1(Xi−Xˉ))]=i=1∑nXi(Yi−Yˉ)−b1i=1∑nXi(Xi−Xˉ)=i=1∑nXi(Yi−Yˉ)−∑i=1n(Xi−Xˉ)2∑i=1nXi(Yi−Yˉ)i=1∑n(Xi−Xˉ)2∵i=1∑nXi(Xi−Xˉ)=i=1∑n(Xi−Xˉ)2=0
將 X 和 e 寫成向量,i.e. X=(X1,⋯,Xn)t∈Rn,e=(e1,⋯,en)t∈Rn,則 Xte=0⟹X⊥e (垂直)。
-
∑i=1nYi^ei=∑i=1nb0ei+b1∑i=1nXiei=0+0, let Y^=(Y1^,⋯,Yn^)t∈Rn
⟹Y^te=0, i.e. Y^⊥e
since e=Y−Y^⟹Y^⊥Y−Y^

所以預測值 Yi^ 是 Y 的投影。
-
擬合的回歸函數 Yi^=Yˉ+b1(Xi−Xˉ) 通過點 (Xˉ,Yˉ)。
最佳線性不偏預測(Best Linear Unbiased Estimator, BLUE)
Q: 最小二乘法總是能得到一個好的 β^ 嗎?或者說,在什麼情況下最小二乘法難以得到一個好的 β?
-
在下圖情況中,如果我們計算殘差 ei,雖然可能會得到和為 0 的結果,但殘差的分佈有很明顯的正負聚集現象。而我們希望殘差的正負隨機分佈的。
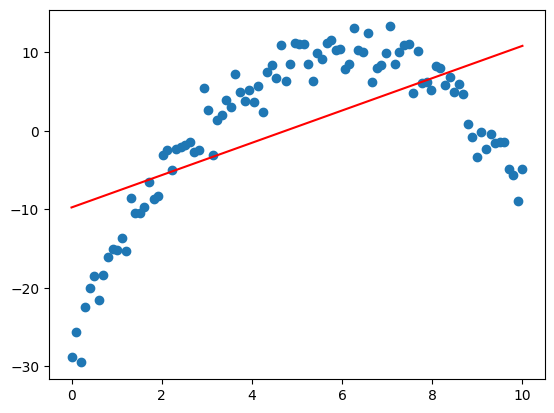
為了避免這種情況,我們需要誤差的期望為 0,即 E[ε]=0。
-
下圖中的數據,隨著 X 的增加,數據也越分散。
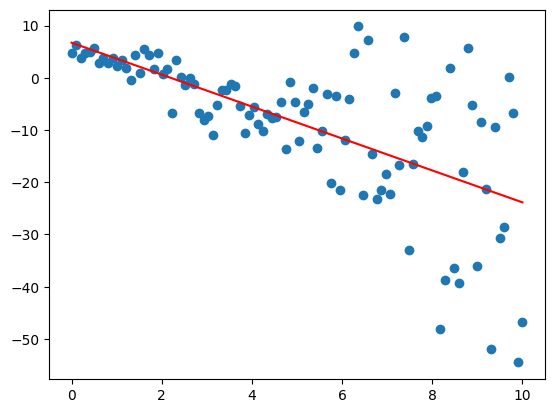
為了避免這種情況,我們需要所有誤差的方差是一樣的,即 Var[e]=σ2,其中 σ2 是一個常數。
-
當沒有按照正規的程序獲取數據時,可能會出現下圖的情況。各個數據之間可能存在著相互關聯的情況。那麼擬合出來的回歸線會存在誤導性。
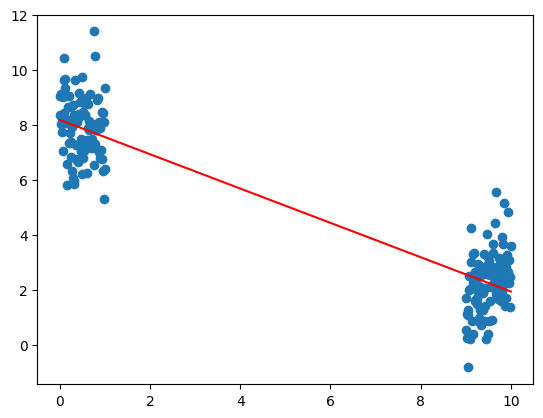
為了避免這種情況,我們需要所有誤差之間是沒有線性關係的,即 Cov[ei,ej]=0,∀i=j。
formal statement of the of linear regression model
Yi=f(Xi;β)+εi=β0+β1Xi,1+⋯+βkXi,k+εiwith the following conditions:
- E[εi]=0
- Var[εi]=σ2{εi}=σ2
- Cov[εi,εj]=σ{εi,εj}=0
我們可以直接得到結論:
- E[Yi]=f(Xi,β) 是回歸函數。
- σ2{Yi}=σ2{εi}=σ2,因為 f(Xi,β) 是一個常數。
- σ{Yi,Yj}=σ{εi,εj}=0.
Recall 對於 SLR,當我們已經拿到數據 X,β0,β1 的 LSE 是:
b0=Yˉ−b1Xˉ,b1=∑i=1n(Xi−Xˉ)2∑i=1n(Xi−Xˉ)(Yi−Yˉ)
⟹E[b1]=∑(Xi−Xˉ)2∑(Xi−Xˉ)EYi=∑(Xi−Xˉ)2∑(Xi−Xˉ)(β0+β1Xi)=β1E[b0]=E[Yˉ−b1Xˉ]=EYˉ−XˉE[b1]=β0+β1Xˉ−Xˉβ1=β0
⟹EYi^=E[b0+b1Xi]=β0+β1Xi=EYi,因此 Yi^ 是 Yi 的無偏估計。
⟹E[ei]≜E[Yi−Yi^]=0
∑wiYi 被稱為線性估計量(linear estimator)。
因此 b0,b1 是 β0,β1 的線性無偏估計。
Gauss-Markov theorem
When E(εi)=0,σ2{εi}=0,σ{εi,εj}=0
Then b are the Best Linear Unbiased Estimators (BLUE) of β.
變異數分析(Analysis of Variance, ANOVA)
我們想要知道目標 Y 的變化量能否被預測值解釋。而变异数分析是在计算数据与均值之间的差异。
Note:
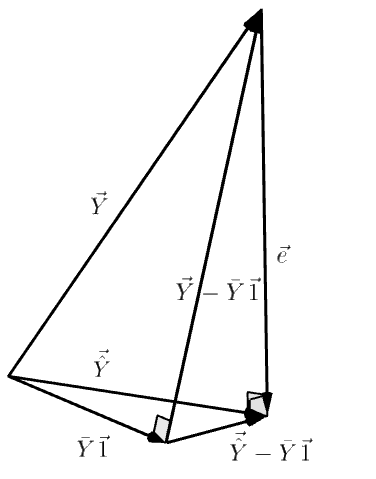
Yˉ⊥e=Y−Yˉ⟹∣∣Y∣∣2=∣∣Yˉ∣∣2+∣∣e∣∣2
∑ei=0⟹e⋅1=0⟹e⊥1
⟹∑[e⋅(Yi^−Yˉ)]=∑eiYi^+Yˉ∑ei⋅1=0⟹e⊥Y^−Yˉ1
⟹∣∣Y−Yˉ1∣∣2=∣∣Y^−Yˉ1∣∣2+∣∣e∣∣2
i.e.SSTO∑(Yi−Yˉ)2=SSR∑(Yi^−Yˉ)2+SSE∑(Y−Yi^)2
SSTOSSRSSE=∑(Yi−Yˉ)2Sum of Squared Total var (Of Y)=∑(Yi^−Yˉ)2Regression Sum of Squares=∑(Y−Yi^)2Error Sum of Squares
- SSTO:表示數據 Y 與其均值 Yˉ 之間的差異,也就是數據的變異量。
- SSR:表示預測值 Y^ 與均值 Yˉ 之間的差異。代表了模型解釋的變異量。SSR 越大,說明模型解釋的變異量越多。
- SSE:殘差的平方和。代表了模型無法解釋的變異量。SSE 越小,說明模型無法解釋的變異量越少。
Fundamental identity
dfSLRMLRSSTOn−1n−1===SSR1k+++SSEn−2n−p=參數量(k+1)
- df: 自由度(degree of freedom)
- k: 自變量的個數
MSE≜n−pSSEMSR≜kSSR Hence, MSE is unbiased for σ2.
在回歸中,我們通常使用 MSE 估計 σ2。而 σ 則用 MSE 估計。
對於 σ2{∗}=σ2⋅c,我們定義一個估計方法:
S2{∗}=MSE⋅c=σ2^{∗}E.g.
σ2{b1}=σ2∑(Xi−Xˉ)21⟹S2{b1}=MSE∑(Xi−Xˉ)21
因此 σ2{∗}S2∗ 的比值永遠會是 σ2MSE。
常態誤差回歸模型(Normal Error Regression Model)
在回歸模型的基礎上,我們進一步假設誤差項 εi 是服從常態分佈的。
Yi=f(Xi;β)+εi,εi∼iidN(0,σ2) 因此 Yi 也會獨立服從 N(f(Xi;β),σ2)。既然 Yi 的分佈是已知的,我們就可以構建它的似然函數。
L(β,σ2)=i=1∏n2πσ21exp(−2σ2(Yi−f(Xi;β))2)=(2πσ2)n/21exp(−2σ21i=1∑n(Yi−f(Xi;β))2)=(2πσ2)n/21exp(−2σ21i=1∑n(Yi−Yi^))2)=(2πσ2)n/21exp(−2σ21Q(β))
⟹ 在 SLR 中,β0^MLE=b0,β1^MLE=b1。並且
σ2^MLE=n1i=1∑n(Yi−Yi^)2=nSSE